Easy-Policy(-Shortener)
Easy-Policy(-Shortener)
</br>
✅ I have read and agree to the Terms.
We all click that box regularely, but rarely know what we are agreeing to.
</br>
Problem & Motivation
— Nobody reads these texts. They matter. —
Privacy policies and terms & conditions (AGB/DSE) are legally important, yet often long and difficult to read, hard to find and inconsistently structured. For users, this means a lack of transparency.
The goal of Easy-Policy is not to solve this problem outright, but to lay the groundwork for a structured and verifiable pipeline.
Our focus lies on extracting, classifying and analyzing legal text from Swiss websites to, in a first step, understand how these documents are structured.
</br>
System Overview
— Find the text. Then the meaning. —
</br>
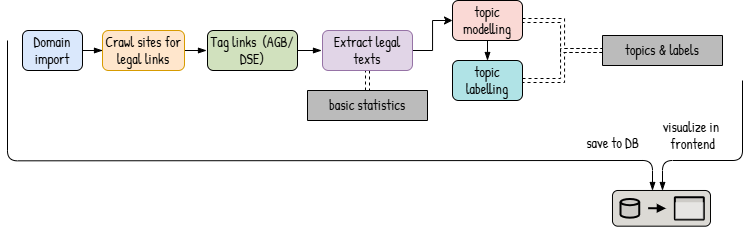
Overview of the processing pipeline, from domain import to frontend display.
Each stage of the process is assigned a color, that is used in both the diagram and the corresponding section below.
</br>
🟦 Domain import
The system relies on a publicly available list of .ch domains that are imported from SWITCH as the initial dataset.
</br>
🟨 Crawl sites for legal links
The system scans the homepage of each domain for internal links that most likely lead to legal texts, using simple pattern matching based on common keywords such as datenschutz, privacy, agb and terms.
Only the homepage of each domain is analyzed, avoiding deeper crawls and no extensive actions to bypass protections have been implemented. This ensures that the content collected reflects what is easily accessible to users, without forcing access to hidden or protected areas.
</br>
🟩 Tag links (AGB / DSE)
Links are classified as a document type (either DSE or AGB) based on simple heuristics, in this case, keyword matches in the URL or link text. If the content could be a legal-text but can’t be clearly assigned, it is labeled legal_unclear as a fallback and for future expansion into more document types. The main focus remains on AGB and DSE documents.
</br>
🟪 Extract Legal Texts
The raw HTML is fetched and processed using jusText, which removes layout elements like menus and footers.
The resulting plain-text document is stored alongside its metadata and serves as the input for all further analysis.
</br>
Extract basic statistics
Basic statistics are calculated to provide an initial understanding of each of these documents and include: language, wordcount, sentence count aswell as the most frequent terms.
</br>
🟥 Topic Modeling (BERTopic)
To identify recurring content patterns, each cleaned document is split into smaller text segments (chunks), which are vectorized. These vectors are passed through UMAP for dimensionality reduction and are then clustered with HDBSCAN, resulting in groups of text that are semantically similar.
Topic modeling is applied separately to AGBs and DSEs to account for structural and thematic differences between the document types.
</br>
🟦 Label Topics (LLM)
To make the topic clusters more interpretable, a local language model (Mistral, via Ollama) is used to assign descriptive labels.
For each cluster, the model receives the top keywords and generates a short title. This labeling step does not aim for legal precision, but rather provides intuitive summaries that help identify the dominant themes in each group.
💡
Running the LLM locally ensures that no document content is transferred to external services and allows the system to remain fully self-contained and privacy-conscious.
</br>
Store & Visualize
Domains, links, extracted texts and their metadata are stored in a PostgreSQL database. Topic clusters and labels are computed dynamically and integrated into the frontend, which offers statistics per document aswell as an overview by document type for comparison. </br> </br>
Results & Interpretation
— What shows up again and again and what doesn’t.—
Topic modeling and label generation were performed separately for both DSEs and AGBs.
To keep this post concise, we’re showing one representative example from the AGB category below.
</br>
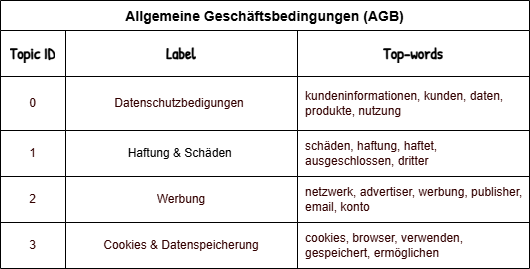
</br>
Each row corresponds to a topic cluster, along with its most frequent terms and the automatically generated label.
The results illustrate recurring topics commonly addressed in AGBs, such as liability clauses, data protection and advertising practices.
While the clusters might not represent legally distinct sections, they reflect consistent structural themes that appear across different websites.
</br>
</br>
Conclusion & outlook
— We’re not done. We just made it possible to begin. —
Easy-Policy demonstrates that even simple methods can make legal web content more transparent and analyzable. While the current implementation focuses on AGBs and DSEs, the pipeline is designed to be modular and expandable. Future steps could include deeper crawls, PDF support or document quality assessments.
</br>
[!NOTE] Want to contribute or explore the system further? Check out the GitHub repo HERE
</br> </br>
Technologies used | Citation
| Component | Technology |
|---|---|
| Domain data | SWITCH |
| Backend | Python, Flask |
| NLP / Clustering | jusText, BERTopic, Ollama, HDBSCAN, UMAP |
| Frontend | Vue 3 |
| Database | PostgreSQL + SQLAlchemy |