Using Machine Learning to Optimize Stablecoin Markets
Stablecoins are digital currencies that aim to maintain a constant value by being pegged to assets like the US dollar. However, even among dollar-pegged stablecoins, small price discrepancies regularly appear on exchanges such as Binance. These temporary imbalances create opportunities for arbitrage.
In this blog post, we present Swabbler, our modular trading system designed to capture these small inefficiencies. We compare three trading strategies, including a deep learning model, and show how machine learning can significantly boost performance in stablecoin markets.
But if we profit from arbitrage, who’s on the losing end?
The answer lies in market mechanics. Our strategies function like traditional market makers: by placing limit orders, we provide liquidity and reduce bid-ask spreads. Traders seeking immediate execution, those who need to buy or sell now, pay a small premium for that convenience. Our profit comes from these premiums, not from exploiting others, but by improving market efficiency.
Our System
Swabbler is an end-to-end trading pipeline built for speed and modularity. It uses sub-millisecond processing to make decisions and integrates historical, sandbox, and live trading capabilities via the Nautilus Trader engine.
We compared three strategies:
| Strategy | Description | Style | Fill Rate | P&L (%) | Sharpe |
|---|---|---|---|---|---|
| Baseline | Static limit orders with thresholds | Passive | 30% | +15.0 | 9.87 |
| PPO Agent | Reinforcement learning (PPO) | Active | 95% | -0.81 | 12.23 |
| GRU Trader | GRU neural net predicting returns | Active | 95% | +19.7 | 26.52 |
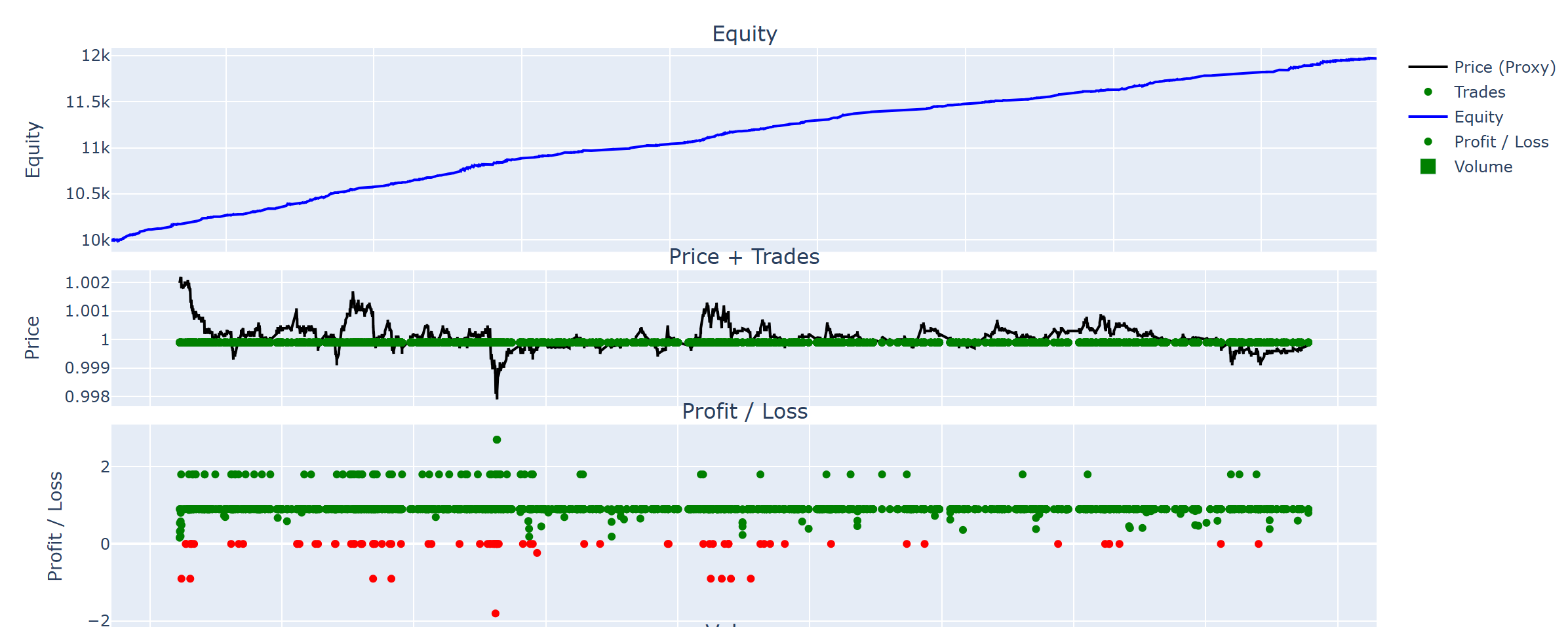
The Baseline (Spot-Gate)
A simple rule-based strategy that alternates between placing buy and sell limit orders. While it achieved a raw backtest profit of +52%, the real-world adjusted P&L dropped to ~15% due to only ~30% of orders being filled.
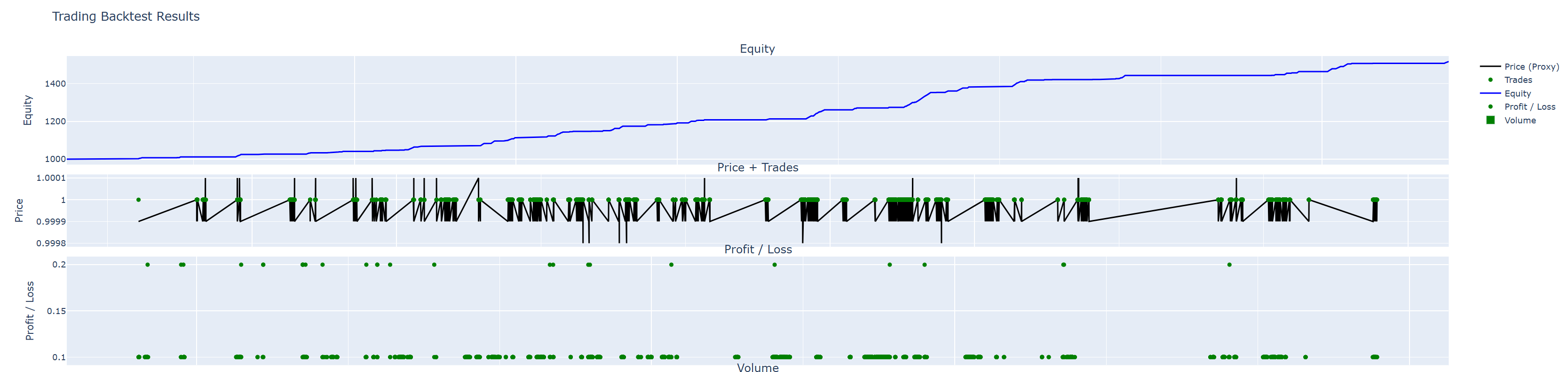
PPO Reinforcement Learning
Our RL agent used Proximal Policy Optimization (PPO) with a 10-dimensional feature vector to dynamically adjust thresholds. Despite promising training metrics, it failed to generalize and incurred losses in live-like conditions.
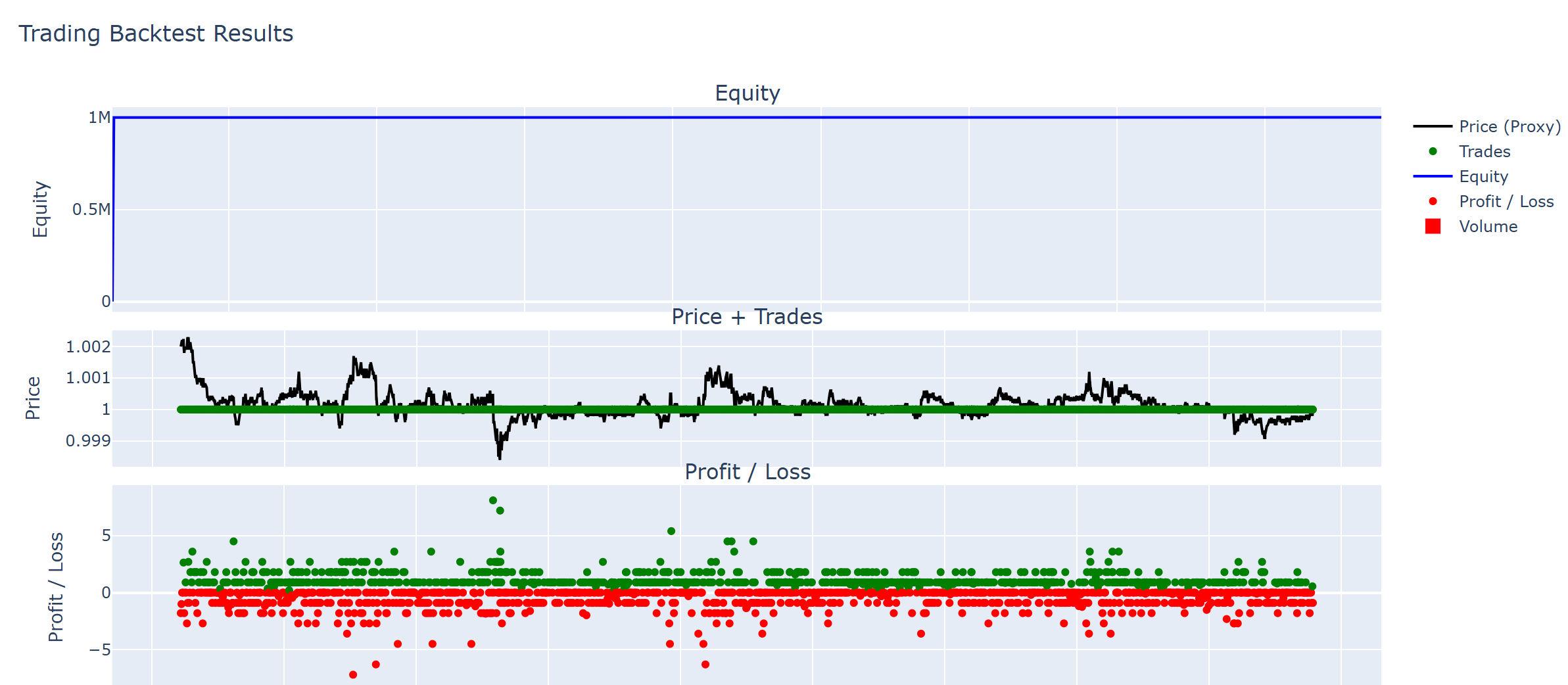
GRU-Based Deep Learning Model
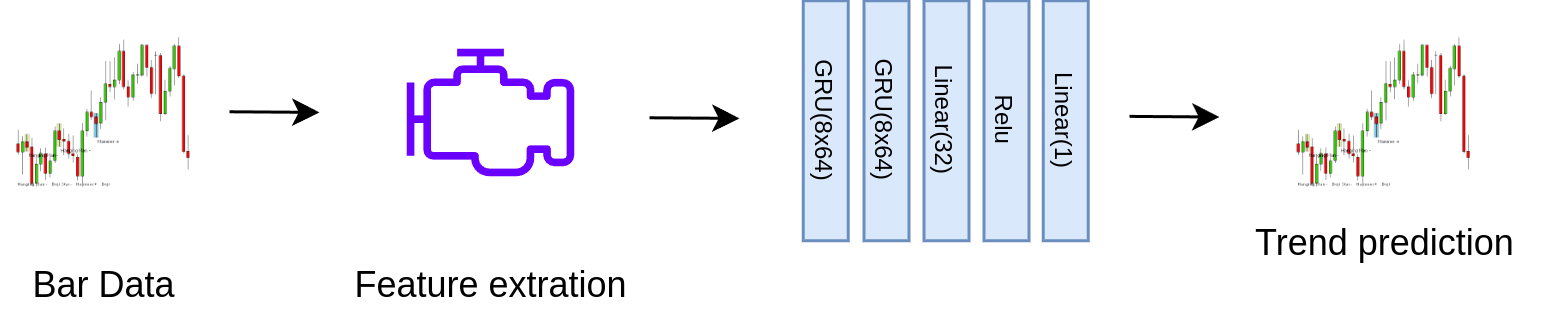
The GRU model uses eight engineered features and 60 minutes of price history to predict future log returns. With a +19.7% return and a Sharpe ratio of 26.5, it proved the most robust and adaptable approach in our tests. The architecture featured stacked GRU layers optimized via Optuna, and inference times remained under 1ms per bar.
Takeaways
Our findings highlight the importance of realistic assumptions in algorithmic trading. While the rule-based baseline appears highly profitable in theory, it underperforms when trade fill rates are taken into account. The reinforcement learning strategy, though adaptive, struggled with the noisy and low-volatility nature of stablecoin markets.
The GRU-based approach emerged as the most promising. It captured short-term trends with high accuracy and operated efficiently even under strict latency constraints. Still, model interpretability and compliance remain challenges for production deployment.
What’s next?
Future work includes:
- Incorporating order book data and queue-based execution simulation
- Extending the RL agent’s action space for more nuanced control
- Enabling online learning for continual adaptation
- Building explainability dashboards for model transparency
Swabbler shows that intelligent automation can unlock value even in seemingly “stable” markets. By marrying fast infrastructure with thoughtful model design, we take a step closer to real-time, machine-learning-driven market making.
Have thoughts or questions? Drop a comment below or follow our project updates for more. The Interactive Plots can be accessed under the following Link: Interactive Plots